Now Reading: Nowe modele GPT-OSS od OpenAI: Przewodnik
-
01
Nowe modele GPT-OSS od OpenAI: Przewodnik

OpenAI właśnie opublikowało modele o otwartych wagach – GPT-OSS 120B i GPT-OSS 20B.
To przełomowa decyzja, która oznacza powrót OpenAI do filozofii “open source” i umożliwia uruchamianie potężnych modeli językowych lokalnie na własnym sprzęcie.
Co to za modele?
GPT-OSS 120B – wielki model do trudnych zastosowań:
- 117 miliardów parametrów (5,1 miliarda aktywnych na token)
- Wydajność porównywalna z o4-mini
- Wymagania – są spore: ~60-80GB VRAM (pojedynczy GPU H100 lub wielokartowe systemy)
- Idealny do zastosowań produkcyjnych i zaawansowanych zadań rozumowania (reasoning)
GPT-OSS 20B – lekki model do codziennej pracy
- 21 miliardów parametrów (3,6 miliarda aktywnych na token)
- Wydajność podobna do o3-mini
- Wymaga jedynie 16GB pamięci
- Do uruchamiania lokalnych aplikacji nawet na laptopach i zwykłych kartach graficznych
Kluczowe cechy
Licencja Apache 2.0 – pełna swoboda komercyjnego wykorzystania, modyfikacji i dystrybucji
Konfigurowalny poziom rozumowania – trzy tryby (niski, średni, wysoki)
Pełny Chain-of-Thought – dostęp do procesu myślenia modelu
Możliwość fine-tuningu – pełne dostosowanie do konkretnych przypadków użycia
Zdolności agentowe – wywołania funkcji, przeglądanie internetu, wykonywanie kodu Python
Natywna kwantyzacja MXFP4 – umożliwia efektywne działanie na pojedynczych GPU
Jak uruchomić lokalnie – instrukcje krok po kroku
Opcja 1: LM Studio (interfejs graficzny)
- Pobierz LM Studio z oficjalnej strony tutaj: https://lmstudio.ai/
- Wyszukaj “gpt-oss” w zakładce Discover, po aktualizacji do wersji 0.3.22 LM Studio sam proponuje instalację modelu gpt-oss-20b:
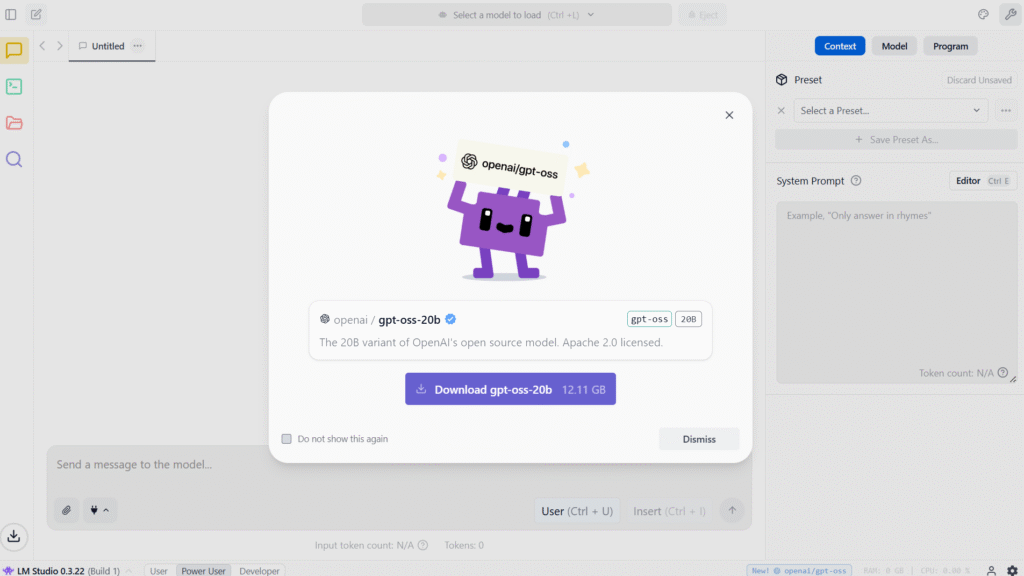
- Pobierz wybrany model (20B lub 120B) – zalecam 20B 🙂 Zajmuje on 12.11GB – to w miarę standardowy rozmiar jak na Lokalny Model LLM.
- Uruchom model w interfejsie chat – “Start a New Chat”
Następnie wpisujesz swój Prompt – wybierasz poziom Reasoing Effort – tak jak pisałem mamy 3 do wyboru (Low, Medium i High).

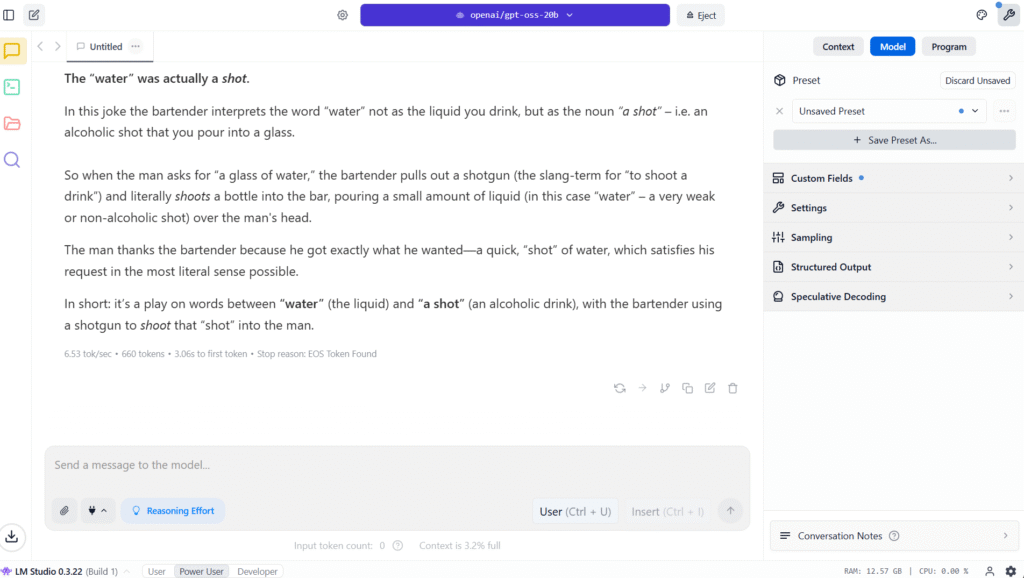
Klikasz Enter – i cieszysz się własnym modelem LLM od OpenAI na swoim komputerze – prawda, że proste! Należy jednak pamiętać, że modele hostowane lokalnie są zazwyczaj znacznie słabsze niż te ogólnie dostępne. W przypadku naszej zagadki – nawet przy ustawieniu rozumowania na High – dostajemy odpowiedź, która pozostawia wiele do życzenia.
W przypadku ustawienia rozumowania na High – model przekroczył kontekst i nie dostałem odpowiedzi. A sama odpowiedź u mnie trwała około 11 min. – Szkoda.
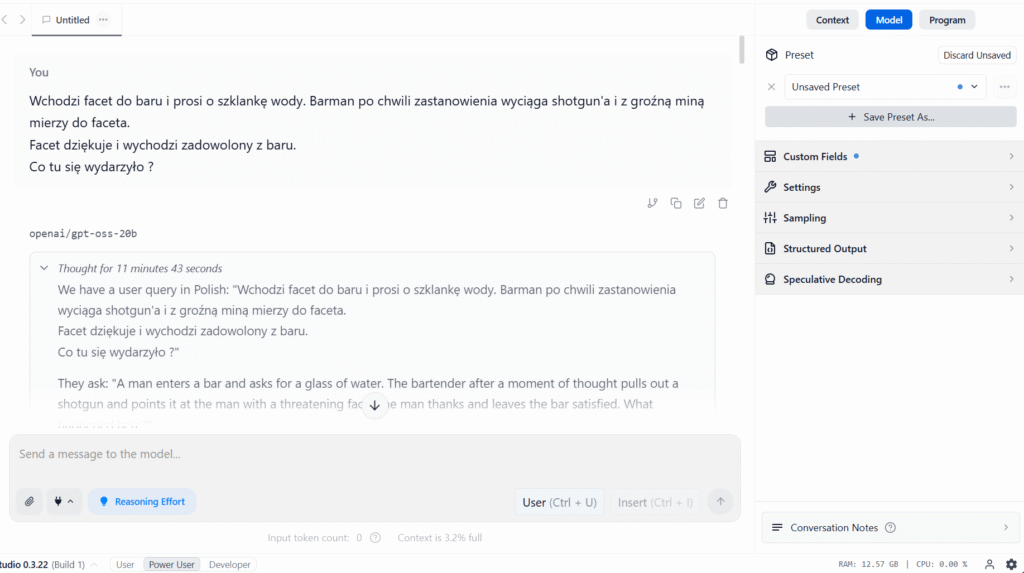
Stwierdziłem więc, że to może wina mojego PC – demonem to on nie jest. I odpaliłem modele Online.
Dla modelu 20B – jest tak samo – brak odpowiedzi:
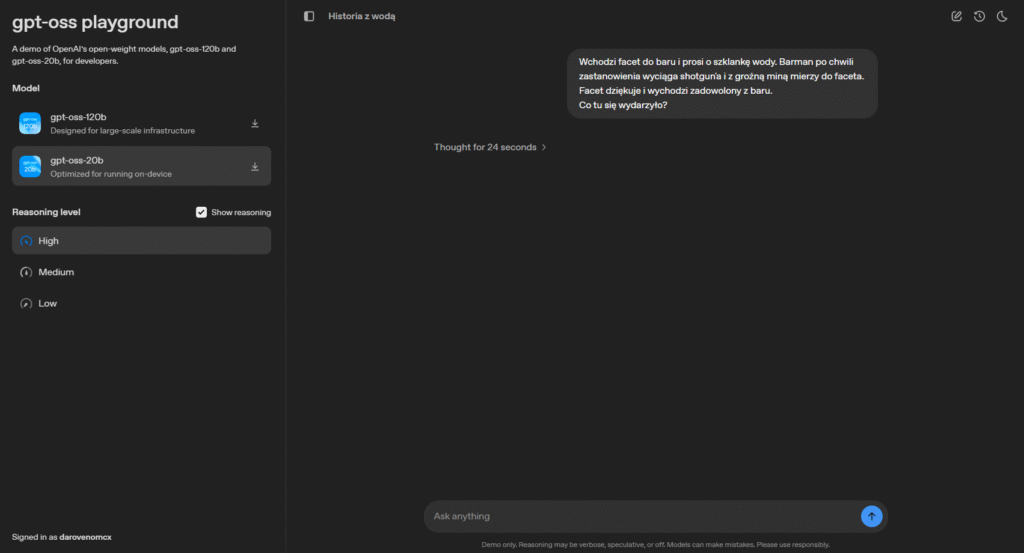
Model 120B jednak sobie poradził całkiem ładnie i szybko (12s). Szkoda tylko, że ma takie wymagania na zasoby.
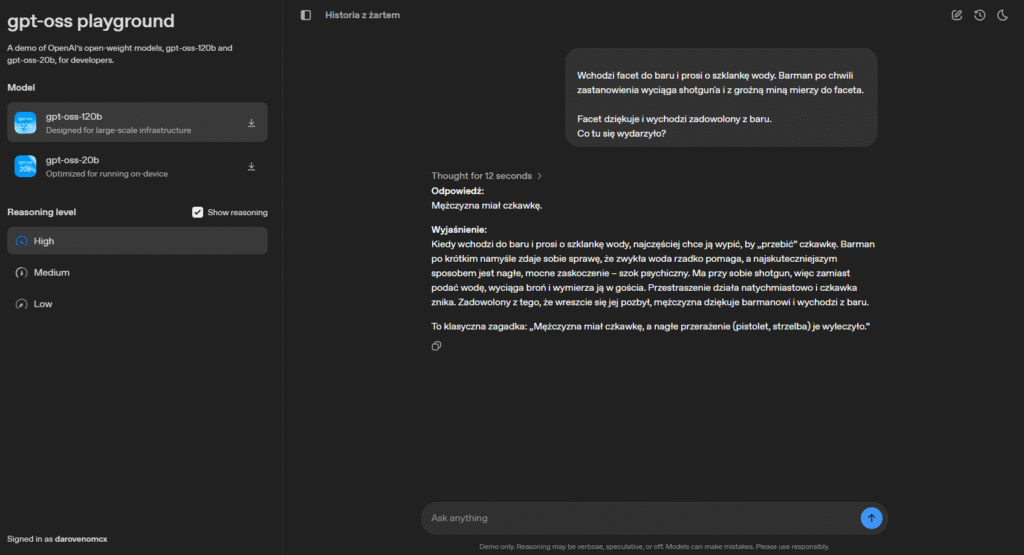
Standardowy ChatGPT od OpenAI radzi sobie z tym znacznie lepiej i szybciej. Więc dla codziennej pracy zostanę jednak przy otwartych modelach.
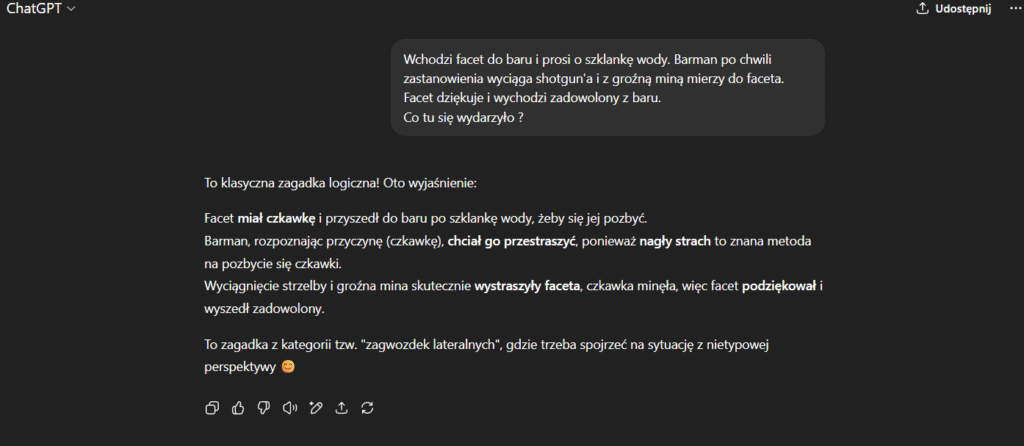
Pokazuje to, że ciągle nawet pomimo liczb podawanych w miliardach – modele lokalne znacznie odstają od swoich rówieśników.
UWAGA: Oczywiście zależnie od mocy obliczeniowej twojego PC może to potrwać znacznie dłużej niż na Otwartych modelach OpenAI.
Opcja 2: Ollama
- Zainstaluj Ollama
curl -fsSL https://ollama.com/install.sh | sh - Pobierz model
ollamapull gpt-oss:20bollama pull gpt-oss:120b - Uruchom model
ollama run gpt-oss:20b - Użyj przez API
from openai import OpenAI
client = OpenAI(
base_url=”http://localhost:11434/v1″,
api_key=”ollama”
)
response = client.chat.completions.create(
model=”gpt-oss:20b”,
messages=[
{“role”: “user”, “content”: “Napisz funkcję Python do sortowania listy”}
])
Opcja 3: Hugging Face Transformers
Bash
pip install transformers torchPython
from transformers import pipeline
# Automatyczne rozmieszczenie na GPU
generator = pipeline(
"text-generation",
model="openai/gpt-oss-20b",
device_map="auto"
)
result = generator("Wyjaśnij machine learning", max_length=200)
Wymagania sprzętowe
Dla GPT-OSS 20B:
- Minimum 16GB RAM/VRAM
- Karty graficzne: RTX 3090, 4090, lub nowsze
- Apple Silicon Mac z 32GB+ unified memory
Dla GPT-OSS 120B:
Dostępność w chmurze
Modele są także dostępne przez:
Related Posts

Stay Informed With the Latest & Most Important News
Previous Post
Next Post









Advertisement




