Now Reading: RAG bez tajemnic – czyli słów kilka o strategiach chunkowania
-
01
RAG bez tajemnic – czyli słów kilka o strategiach chunkowania
Cel wpisu
Na początku skupimy się na tym jak znane modele jak OpenAI oraz Claude przechowują wasze dane w swoich rozwiązaniach. Na końcu zrobimy przegląd, tego w jaki sposób podchodzi się do tworzenia RAG i baz wiedzy dla rozwiązań klasy Enterprise i jakie są podstawowe różnice między dzieleniem treści na części (chunkowaniem) i co z nich wynika.
Co wiemy o tym jak OpenAI i Claude dzielą dane w bazach wiedzy?
Różnice są ogromne – a dokumentacja niepełna
LLM-y jak OpenAI GPT i Claude pozwalają wprawdzie na dodawanie własnych plików do bazy wiedzy, ale sposób w jaki te platformy dzielą nasze dane na fragmenty (chunki) jest nadal mocno okryty tajemnicą. Po przebadaniu oficjalnych źródeł i dyskusji developerskich jasne jest jedno: różnice między podejściami są większe niż mogłoby się wydawać.
Dla osób mniej technicznych – obecnie niemal każdy ważny gracz w świecie AI pozwala na tworzenia własnych Agentów/Projektów i podpinanie pod nie swoich baz wiedzy. W przypadku ChataGPR robimy to tworząc nowy projekt i dodając swoje pliki tak jak na moim screenie:
Na podstawie tych plików – w moim przykładzie są to dane o mnie. Agent może udzielać odpowiedzi w oparciu o dostarczony przeze mnie Kontekst – a nie w oparciu o swoją ogólna bazę wiedzy. (O tym jak to działa w praktyce napisze w osobnym artykule).
Na teraz ważne jest to, że po dodaniu moich danych jeżeli zapytam Chata np. o to co lubię robić, odpowie na podstawie moich danych. U mnie wygląda to tak:

Dlaczego pliki MD
To temat na osobny artykuł – ale chodzi o strukturę. Format Markdown pozwala na wskazanie czym jest dana treść – czego nie można zrobić w dokumentach WORD i PDF.
W tym punkcie – pojawia się odpowiedź na pytanie czemu wiele osób mówi, że LLM Halucynuje na ich danych. Jeżeli wrzucimy dla LLM wszystkie nasze pliki i dokumenty – i nie popracujemy nad ich strukturą i treścią – to LLM będzie wybierał je na “chybił trafił”.
Dla moich klientów podaję bardzo prosty przykład – w dokumentach firmowych często mamy procedury. Procedury z reguły są ważne przez pewien okres czasu, po czym zastępowane są nowymi procedurami. Ich treść zazwyczaj jest podoba. Jeżeli wrzucimy do LLM – wszystko co mamy – czyli stare procedury i nowe i nie wskażemy mu, która jest aktualna – mamy przepis na “katastrofę”.
LLM nie domyśli się sam, że np. ta z najnowszą datą dodania jest obowiązująca – w sumie przecież wcale tak być nie musi ? Prawda ?
Jak robią to popularne modele?
OpenAI: Kontrolowane parametry, ale ograniczona przejrzystość
OpenAI w swoim Assistant API File Search stosuje fixed-size chunking z overlap, ale przynajmniej udostępnia podstawowe parametry do konfiguracji:
- Domyślny rozmiar chunka: 800 tokenów
- Overlap: 400 tokenów (50% nakładania)
- Model embeddingu: text-embedding-3-large z 256 wymiarami
Można te parametry modyfikować przy tworzeniu vector store:
pythonvector_store = client.vector_stores.create(
name="my_store",
chunking_strategy={
"type": "static",
"static": {
"max_chunk_size_tokens": 600,
"chunk_overlap_tokens": 200,
}
}
)
Algorytm samego dzielenia pozostaje czarną skrzynką. OpenAI nie ujawnia jak dokładnie traktuje różne typy plików – czy PDF z tabelami jest chunkowany inaczej niż zwykły tekst? Co więcej, automatyczne dzielenie następuje po przesłaniu pliku, więc użytkownik nie ma wpływu na strukturę przed procesem chunkowania.
No dobra – ale co znaczy: fixed-size chunking z overlap ? I w ogóle co to jest ten chunking 🙂
Najprościej rzecz ujmując – gdy dodajemy tekst do modelu LLM – musi on sobie ten tekst jakoś zapisać w bazie. Żeby to zrobić – musi go podzielić na mniejsze części. Fixed-size chunking oznacza, że dzielimy te części po równo. Overlap – oznacza, że żeby LLM wiedział jaka jest zależność między nimi dodajemy trochę tekstu z wcześniejszego fragmentu i trochę z kolejnego. Można to porównać to dzielenia na zakładkę. W przykładzie poniżej zauważcie, że chunk nr 2 zawiera jedno zadanie chunka nr 1 oraz jedno zadanie chunka nr 3. To jest oczywiście wizualizacja:

Wielkość kontekstu vs chunking w OpenAI
Ciekawy aspekt to maksymalny limit tokenów na request: 300 000 tokenów dla wszystkich embeddingów łącznie. To oznacza, że nawet jeśli pojedynczy chunk może mieć maksymalnie 8191 tokenów (dla text-embedding-ada-002), w jednym zapytaniu można przetwarzać znacznie więcej danych. (Chunków). Co to znaczy?
Jeżeli pytacie OpenAI o coś – to on do kontekstu może dodać bardzo dużo chunków i na tej podstawie udzielić odpowiedzi. Nie macie jednak żadnej kontroli nad tym jak wybiera te dane.
Claude: Mniej kontroli, więcej automatyzacji
Claude podchodzi do problemu zupełnie inaczej. Nie ma dostępnych parametrów konfiguracji chunkowania. Anthropic stosuje podejście “black box” – system automatycznie analizuje przesłane dokumenty i decyduje o optymalnym podziale.
Co wiemy o podejściu Claude:
- Limit pliku: 30MB per plik w projektach
- Typy plików: DOCX, PDF, CSV, TXT, HTML, EPUB, JSON, XLSX
- PDF processing: Do 100 stron z analizą wizualną, powyżej – tylko tekst
- Chunking: Całkowicie automatyczny, bez możliwości konfiguracji
Claude zdaje się stosować inteligentniejsze, adaptacyjne chunkowanie oparte na semantycznej analizie dokumentu. System może analizować strukturę dokumentu i dzielić go w miejscach naturalnych podziałów treści, zamiast ślepo przestrzegać stałego rozmiaru.
Contextual Retrieval – nowa jakość od Anthropic?
Anthropic chwali się, że wprowadził Contextual Retrieval – technikę dodającą kontekst do każdego chunka przed embeddingiem.
Po ludzku zamiast zapisywać np. taki tekst jako:
“Przychody firmy wzrosły o 3% w stosunku do poprzedniego kwartału”
System automatycznie rozszerza go do:
“Ten fragment pochodziczy z raportu SEC dotyczącego wyników ACME Corp w Q2 2023; przychody poprzedniego kwartału wyniosły 314 mln USD. Przychody firmy wzrosły o 3% w stosunku do poprzedniego kwartału”
To podejście redukuje błędy pobierania danych (retrieval) o 35% ale wymaga dodatkowych kosztów obliczeniowych przez wykorzystanie Claude Haiku do generowania kontekstu.
Różnice w strategiach
OpenAI
- Przewidywalność: Każdy chunk ma podobny rozmiar
- Prostota: Łatwe do debugowania i optymalizacji
- Efektywność: Niskie koszty obliczeniowe
- Problem: Może przecinać związane semantycznie fragmenty
Z domyślnymi parametrami (800 tokenów + 400 overlap), maksymalnie 20 chunków = ~16 000 tokenów w kontekście retrieval. To dość konserwatywne podejście, które pozostawia miejsce na inne elementy promptu.
Claude
- Inteligencja: Respektuje naturalną strukturę dokumentu
- Kontekst: Zachowuje spójność semantyczną
- Elastyczność: Różne rozmiary chunków w zależności od treści
- Problem: Brak kontroli i nieprzewidywalne wyniki
Brak oficjalnych limitów dla chunków, ale 30MB limit per plik oznacza potencjalnie dużo większe fragmenty tekstu w kontekście. Claude może operować na znacznie dłuższych fragmentach, co może być zarówno zaletą (więcej kontekstu) jak i wadą (więcej “szumu”).
Jak do tego podchodzimy w rozwiązaniach klasy Enterprise
W rozwiązaniach Enterprise budowa RAG i wybór strategii chunkowania to tak naprawdę najważniejsza cześć procesu. Możemy mieć najlepszy model, najlepsze rozwiązanie – ale jeżeli mamy dane słabej jakości i źle podzielone – samo rozwiązanie może okazać się stratą pieniędzy i czasu. Jakie więc mamy opcje i kiedy je stosować ?
UWAGA: W tym artykule nie skupiam się na łączeniu modeli i aspektach związanych z Agentic RAG. Skupiamy się tutaj na tym jakie mamy opcje oraz kiedy najlepiej je stosować.
Fixed-size chunking
Omawiany wcześniej na bazie OpenAI. Jedna z najbardziej podstawowych metodyk. Dobra to zastosowań NIEKOMERCYJNYCH. W praktyce w rozwiązaniach Enterprise w mojej opinii – nie znajduje dla niej zastosowania.
Na przykładzie Inwokacji wyglądało by to tak:

Kiedy stosujemy:
- Dane nieustrukturyzowane – tutaj Pan Tadeusz jest dobrym przykładem. W praktyce – o czym pisałem – takie dane zazwyczaj są bardzo niskiej jakości. Dlatego uważam, że ten model nie przyda nam się do profesjonalnych zastosowań.
- Przyda się dla treści OCR, Contentu pobieranego ze stron WWW crawlerami, dla zeskanowanych dokumentów.
Sliding window
Nazywany także Fixed-size with overlap. Jest to schemat stosowany przez OpenAI, opisywany wyżej. Jest on bardziej skuteczny od poprzedniego – ale dalej nadaje się tylko dla danych nieustrukturyzowanych. Wiec ma ograniczone zastosowanie dla danych niskiej jakości.
Kiedy stosujemy:
- Analogicznie jak dla Fixed-size
- Zaletą jest to, że zadziała lepiej dla contekstów, które samodzielnie są trudne do zaklasyfikowania. LLM w prostszy sposób zachowa kontekst i ciągłość wypowiedzi.
- UWAGA: Ze względu na ovarlap – dane zajmują w bazie więcej miejsca. + LLM zużywa więcej tokenów.
Sentence-Based / Line by Line chunking
Kolejne modele, które stosujemy dla danych nieustrukturyzowanych. Podaję bardziej jako ciekawostkę.
W przypadku Inwokacji wyglądało by to tak:

Kiedy:
- Np. dla tekstów pisanych prozą, wierszem itd.
- UWAGA: Przy podejściu chunkowania po zdaniach – niektóre mogą być za krótkie aby miały wartość i kontekst.
Paragraph Chunking/Section or Heading-Based Chunking
Tutaj dochodzimy do miejsca – gdzie pojawiają się rozwiązania pozwalające na więcej kontroli oraz lepsze indeksowanie danych ustrukturyzowanych.
Heading Based Chunking – jest to moja ulubiona metoda dla dzielenia np. artykułów blogowych.
Znakomicie nadaje się do tego format MD – gdzie każdy artykuł możemy podzielić na odpowiednie sekcje. W tym miejscu dla prezentacji odchodzimy od przykładu inwokacji.
Weźmy przykład artykułu:
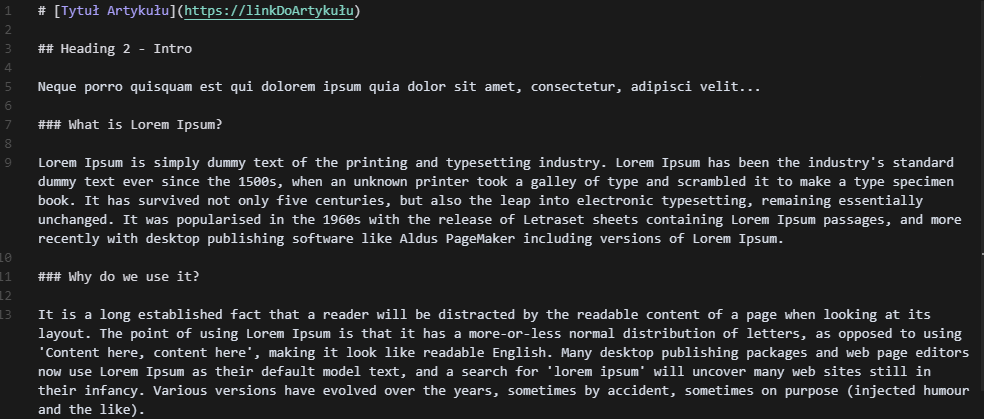
Każdy artykuł możemy dodać jako osobny plik MD.
Do każdego chunku – jako osobne pole w bazie danych możemy dać TITLE – Artykułu w którym dana sekcja się znajduje.
W przykładzie mielibyśmy dla tego artykułu 2 chunki: What is Lorem Ipsum? oraz Why do we use it?
Dla każdego chunku – możemy też dodać w bazie LINK do artykułu nadrzędnego.
Zapytasz – dlaczego jest to lepsze od rozwiązań wyżej:
- Kontrola kontekstu – w momencie gdy artykuł jest długi a do LLM chcemy przekazać np. tylko jeden rozdział bo o niego pyta użytkownik – przekazujemy tylko jeden rozdział – a nie cały artykuł. Zachowujemy jednak dla chunku kontekst całości – więc zawsze możemy dodać informacje skąd pochodzi tekst – tutaj poprzez podanie Tytułu i Linku do artykułu.
- Mniejsza ilość tokenów – zamiast to kontekstu dodawać cały artykuł – przekazujemy tylko to co nam potrzebne
- Produkcyjnie pozwala nam to zniwelować zużycie tokenów z poziomu 50 000 do nawet 6 000 per zapytanie. Daje to prawie 10x oszczędności dla naszych klientów.
- UWAGA: Dla zastosowań indywidualnych – nie ma to aż takiego znaczenia – ale gdy mówimy o rozwiązaniu dla 5000 użytkowników oznacza to oszczędności na poziomie setek lub tysięcy USD.
Page based chunking
Pewną spotykaną odmianą wcześniejszego rozwiązania jest rozwiązanie oparte o strony. Co do zasady – można je stosować dla danych, które nie posiadają tak dobrej struktury jak artykuły – ale w których potrzebujemy odnośnika do numeru strony, lub dane są podzielone per strony np. Katalogi produktów gdzie każdy produkt prezentowany jest na oddzielnej stronie.
Przykład: W kilku rozwiązaniach intranetowych dla klienta ważne było aby przy odpowiedzi LLM podawał numer strony procedury na której jest szukany fragment. Było to podyktowane tym, że procedury miały niekiedy po 200 stron i ważne było aby można było szybko otworzyć dokument na danej stornie.
Keyword-based chunking
Strategia polega na tym, że dzielimy treść po wystąpieniu danego Keyworda. Najczęściej stosowane np. przy embedowaniu przepisów kulinarnych czy treści posiadających zawsze taką samą strukturę – np. kart produktu. W takim przypadku dzielenie po Headerach – nie wiele nam wnosi – granulacja mogła by być zbyt duża.
Przykład:
Standardowo przepis składa się zawsze z kilku sekcji oznaczanych nagłówkiem H2. Nazwa przepisu jest nagłówkiem H1. Sekcje Składniki, Sposób przygotowania, Sposób podania itd. są już sekcjami H2. Strategia dzielenia po nagłowkach – w tym przypadku była by mało pomocna – bo Składniki trafiły by do innego chunku niż sposób przygotowania – raczej słabe.
Dlatego w tym przypadku możemy dzielić chunku po Keywordzie “Składniki” – wtedy mamy pewność, że cały przepis trafi do jednego Chunku.
Table chunking
Często w rozwiązaniach, które realizujemy mamy do czynienia nie tylko z treściami w formatach tekstowych – ale także w formie tabel Excel.
Popularnym przykładem są np. wszelkiego rodzaju formularze np. formularz podatności oprogramowania ASVS: https://owasp.org/www-project-application-security-verification-standard/
Często uzupełnianie takich dokumentów trwa bardzo dużo czasu gdyż takie ankiety mogą mieć po 200-500 pytań.
W praktyce każda linia tekstu to coś w stylu:
| Obszar | Opis wymagania | Poziom spełnienia przez dostawcę |
| Wymagania ogólne | Rozwiązanie zapewnia ochronę przed zagrożeniami zawartymi w OWASP Top 10 | Spełnia |
W takim przypadku – firmy często posiadają często dziesiątki wcześniej uzupełnionych ankiet i chciały by zasilić nimi LLM. Wrzucenie takich plików do standardowego Modelu np. OpenAI – zazwyczaj jest bardzo nieprecyzyjne i obarczone ryzykiem.
W takim przypadku zazwyczaj buduje się RAG w oparciu właśnie o Table chunking. Gdzie każdy chunk – to tak naprawdę osobny wiersz z bazy danych. Analogicznie podchodzimy do tematu danych raportowych.
Recursive chunking/Hierarchical Chunking
Jest to zaawansowana technika w przypadku gdy chcemy zaindeksować wiele dokumentów dla których niektóre są ustrukturyzowane, niektóre nie są – a dla niektórych np. dzielenie sekcji po nagłówkach przekroczy nam Token window dla modelu Embedującego.
W praktyce przy dużych zbiorach danych – zazwyczaj strategia podziału sprowadza się właśnie do tej metody lub jednej z jej odmian.
Jak to działa w praktyce:
Krok 1: Sprawdzamy czy dokument posiada strukturę nagłówków np. H1
NIE: Dzielimy go metodą Fixed Size
TAK: Przechodzimy do kroku 2
Krok 2: Sprawdzamy czy dokument w zakresie nagłówków H1 ma nagłówki H2
NIE: Przechodzimy do kroku 3
TAK: Przechodzimy do kroku 4
Krok 3: Sprawdzamy czy sekcja w nagłówku zmieści się w oknie modelu Embedingowego. np. dla text-embedding-3-small to 8191 tokenów.
TAK: Embedujemy całą sekcję.
NIE: Dzielimy sekcję metodą Fixed Size. Zachowując dla każdej nagłówek H1
Krok 4: Wykonujemy Krok 3 dla nagłówków H2 i kolejnych.
Content-type aware chunking
Najbardziej zaawansowana metoda stosowana przy dzieleniu danych. Polega na budowaniu RAG w taki sposób, że system automatycznie wykrywa typ contentu i na jego bazie dostosowuje strategię chunkowania do wprowadzonych danych. W praktyce daje mniejsza kontrolę ale większą elastyczność.
W praktyce może być zastąpiony kilkoma bazami RAG i podejściem Agentic RAG – gdzie agent główny decyzję na bazie pytania użytkownika – których osobnych baz RAG użyć do udzielenia odpowiedzi. Pozwala to na odseparowanie danych różnych typów i łatwiejszy monitoring rozwiązania.
Kiedy stosujemy:
- Kiedy chcemy odseparować Tabele od Textu i tabel w mechanizmie pobierania danych z RAG (Retrieval) i dostarczaniu ich do kontekstu LLM.
- Umożliwia pobieranie danych zgodnie z kontekstem np.: “Udziel danych na podstawie danych analitycznych z BI.”
RBAC RAG – czyli gdzie zaczyna się “zabawa” w profesjonalne rozwiązania LLM.
Praktyka pokazuje, że w dużych organizacjach – każdy użytkownik posiada różny dostęp do różnych danych. Fakt ten uniemożliwia tworzenie aplikacji w oparciu o proste rozwiązania i ogólna dostępne LLM. Trudno wyobrazić sobie sytuację, gdy wdrażamy LLM i użytkownik, który normalnie nie powinien posiadać dostępu do danych poufnych firmy uzyskuje je poprzez zapytanie do LLM.
W takich rozwiązaniach konieczne jest łączenie mechanizmów RAG z mechanizmem kontroli dostępu RBAC. W praktyce oznacza to, że każdy chunk, który został zaindeksowany w RAG oprócz standardowych informacji posiada informacje o poziomie dostępu do danych w nim zawartych. Dzięki temu na etapie pobierania danych do kontekstu możliwe jest przekazanie do LLM tylko danych do których dany użytkownik – wysyłający zapytanie faktycznie ma dostęp.
To tutaj pojawia się różnica między rozwiązaniami Enterprise, a rozwiązaniami, które można zrealizować w oparciu o otwarte rozwiązania jak Claude, Gemini czy OpenAI.
Bardzo częstym podejściem jest tutaj np. wykorzystanie danych zawartych w ElasticSearch oraz zamkniętego i bezpiecznego modelu jakim jest np. AzureAI.
Więcej o tym można poczytać np. tutaj:
Podsumowanie
Profesjonalne wykorzystanie LLM w biznesie wymaga zupełnie innego podejścia do zarządzania danymi niż rozwiązania na własny użytek. OpenAI i Claude różnią się metodami dzielenia dokumentów na fragmenty (chunki) – OpenAI stosuje przewidywalne, stałej wielkości chunkowanie z overlap, zaś Claude wykorzystuje adaptacyjne, semantyczne podziały dostosowane do struktury dokumentu.
W rozwiązaniach klasy Enterprise kluczowa jest odpowiednia strategia chunkowania oraz kontrola dostępu (RBAC), które zapewniają precyzję i bezpieczeństwo odpowiedzi, zwłaszcza przy dużych bazach wiedzy i wielu użytkownikach.
Podstawowa różnica między rozwiązaniami „amatorskimi” a profesjonalnymi leży w architekturze danych i dopasowaniu procesu chunkowania do specyfiki i jakości danych. Bez tej świadomości inwestycja w zaawansowane modele AI może nie przynieść oczekiwanych efektów i może przekształcić się w wizerunkową katastrofę.

Stay Informed With the Latest & Most Important News
Previous Post
Next Post









Advertisement



